LSTM & GRU
Parte 3
Marcelo Finger Alan Barzilay

Roteiro
- Revisão de AL
- LSTMs
- GRUs
- Redes Bidirecionais
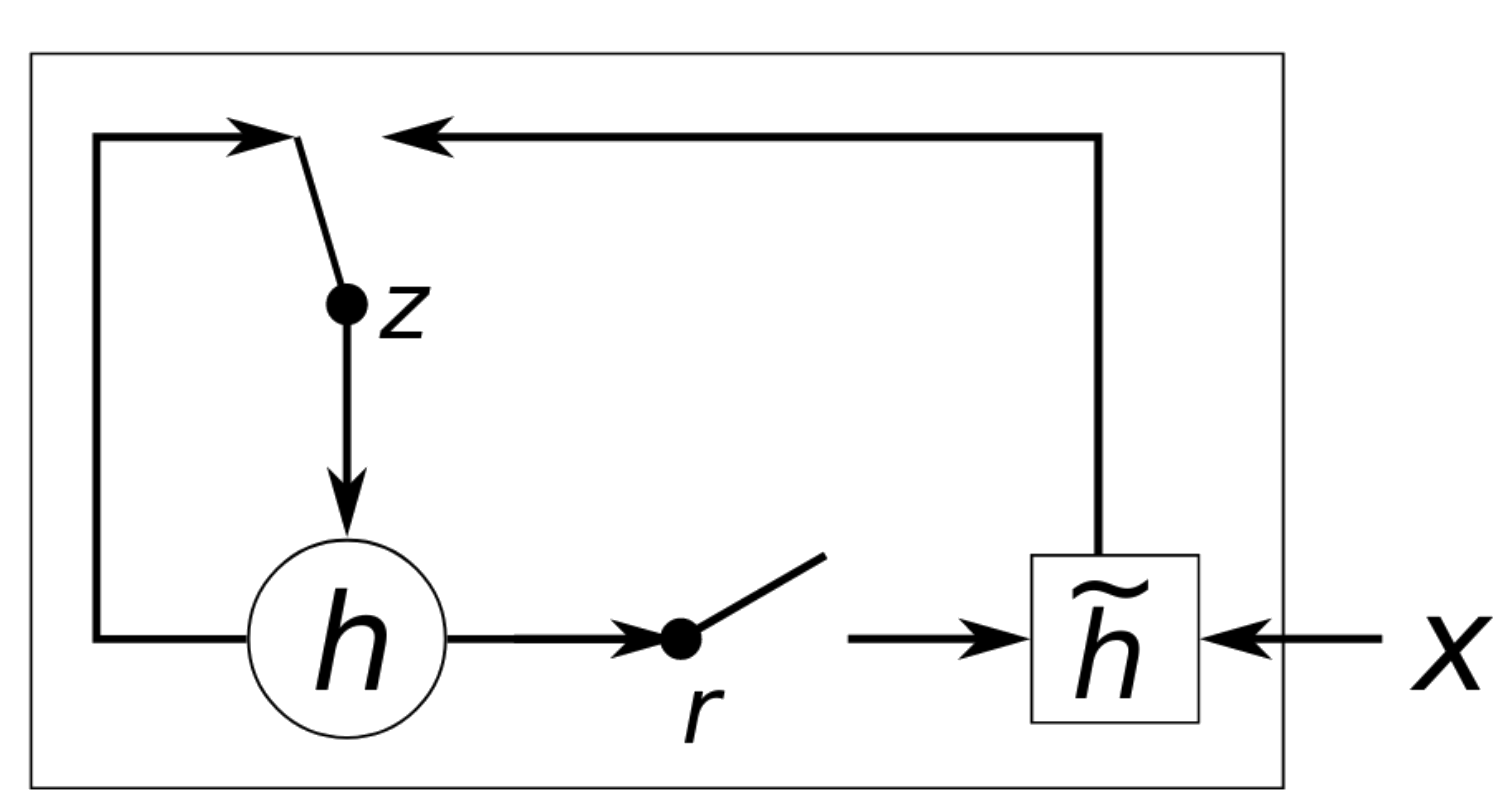
GRU: Gated Recurrent Unit
Forget e input gates são unidos em um unico update gate z
Cell state e hidden state passam a ser uma única entidade

-
Update Gate z controla se o estado h deve ser atualizado com \(\tilde{h}\)
- Reset Gate r controla se o estado h anterior deve ser ignorado
tf.keras.layers.GRU(
units,
activation="tanh",
recurrent_activation="sigmoid",
use_bias=True,
kernel_initializer="glorot_uniform",
recurrent_initializer="orthogonal",
bias_initializer="zeros",
kernel_regularizer=None,
recurrent_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
recurrent_constraint=None,
bias_constraint=None,
dropout=0.0,
recurrent_dropout=0.0,
implementation=2,
return_sequences=False,
return_state=False,
go_backwards=False,
stateful=False,
unroll=False,
time_major=False,
reset_after=True,
**kwargs
)
Usos de LSTMs e GRUs
- São tipicamente usadas em modelos seq2seq
- Uma LSTM/GRU como encoder, uma LSTM/GRU como decoder
- Quando treinadas com grandes quantidades de dados, geram Modelos (Neurais) Recorrentes de Linguagem
- O código gerado pode ser ligado a outras redes para classificação, regressão ou tradução
GRU vs LSTM
LSTM é um pouco mais poderosa (captura mais padrões do contexto)
GRU é mais rápida de ser treinada
Quando usar cada uma?
Dificilmente você encontrará uma RNN pura sendo usada, mesmo para arquiteturas encoder decoder é mais comum usarmos LSTM, GRU, ou outras redes derivadas.
