Marcelo Finger Alan Barzilay

RNN's
Parte 05: Soluções para Redes Profundas
Conteúdos
- Recorrência Neural
- Treinamento Recorrente
- Modelos Sequência pra Sequência
- Problemas que Advem da Recorrência
- Soluções para Redes Profundas
Soluções para Redes Profundas
Como combater Vanishing Gradient?
ReLu
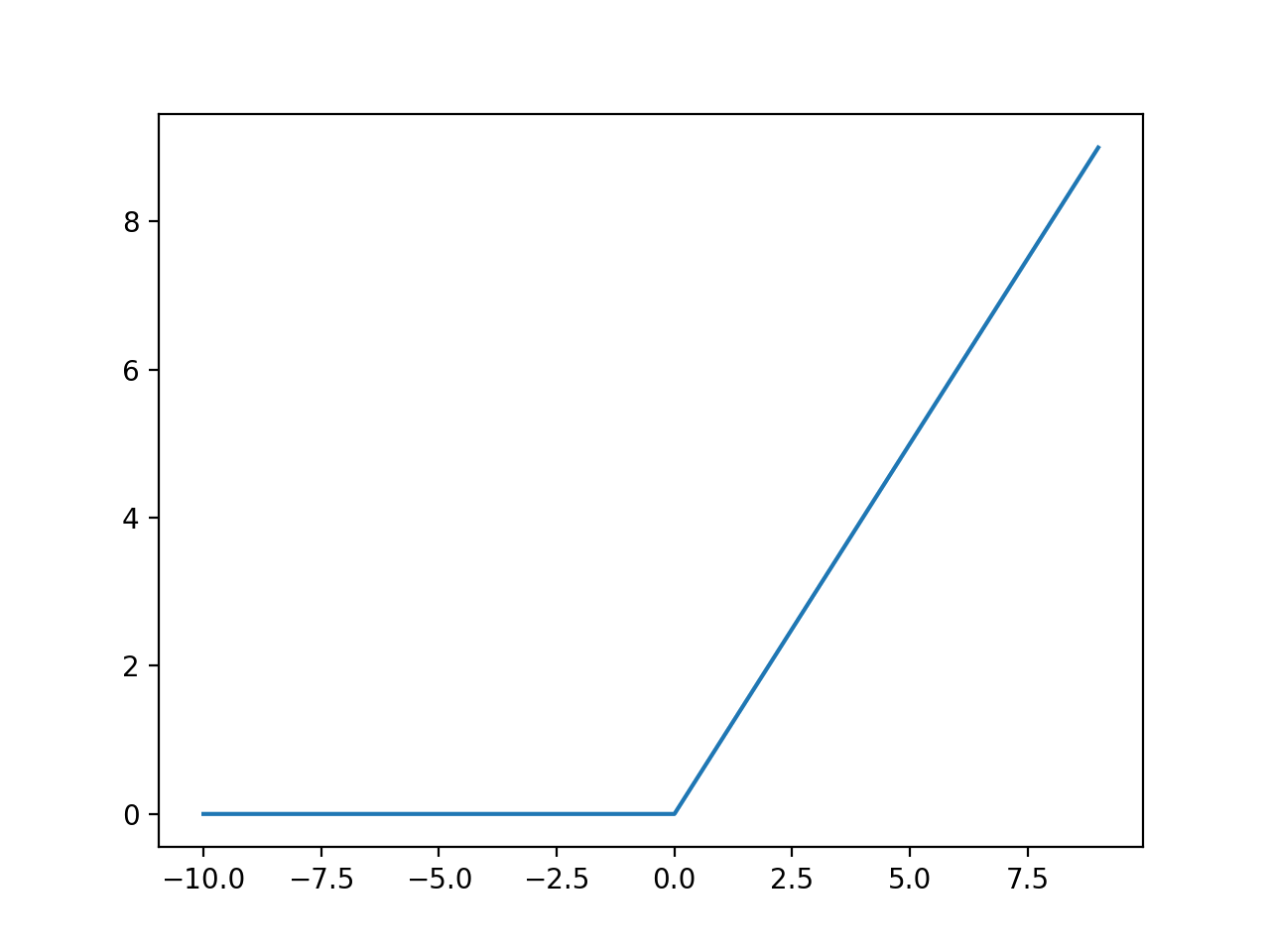
ReLu(x)=max(0,x)
ReLu
Gradiente não fica saturado como \(tanh(x)\)
Como combater Vanishing Gradient?
Conexões Densas
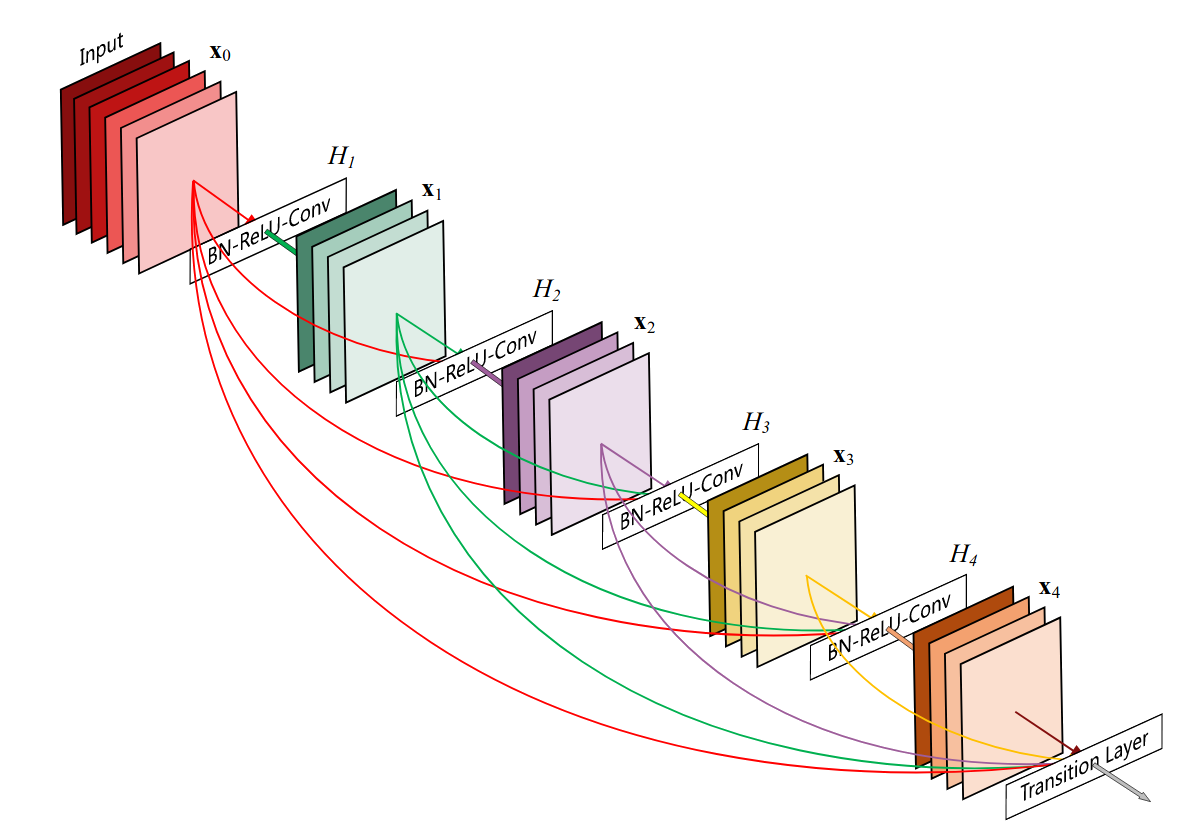
Conecte tudo com tudo
Como combater Vanishing Gradient?
Residual Connections
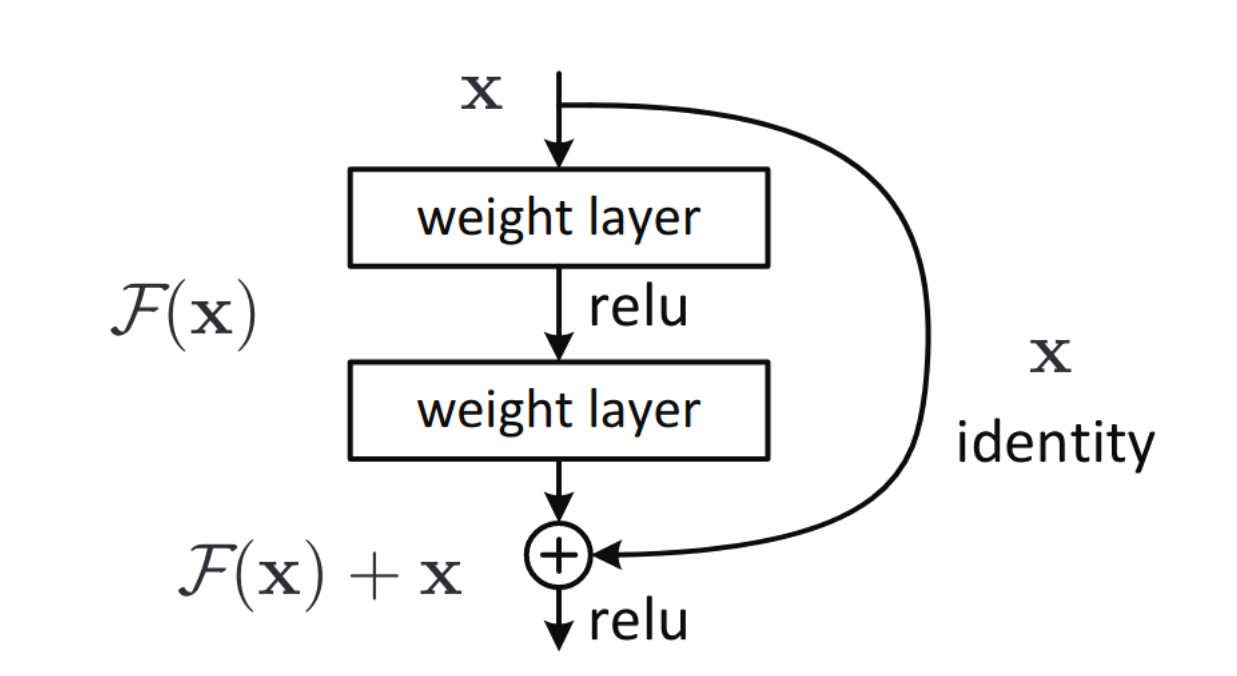
Também conhecidas como Skip-Connections.
São utilizadas no modelo Transformer
Como combater Vanishing Gradient?
Batch Normalization
Normalizar ajuda a impedir que as ativações saturem ao confiná-las em uma região.
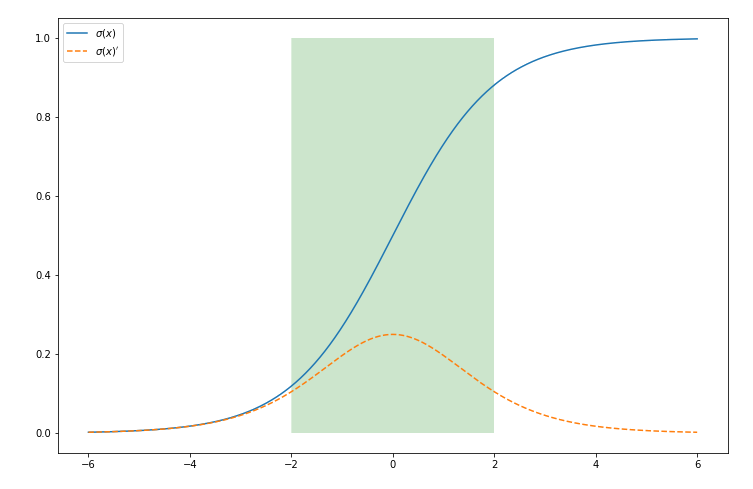
Como combater Vanishing Gradient?
Uma inicialização muito baixa nos leva a vanishing gradient e uma inicialização muito grande nos leva a exploding gradient.
Como podemos inicializar os pesos de uma maneira apropriada?
- Inicialização de Xavier Glorot para ativações simétricas (como a tanh)
- Inicialização de Kaiming He para ativações assimétricas (como a ReLu)
Como combater Vanishing Gradient?
