Word2vec
Parte 02: Detalhando o Modelo Básico
Marcelo Finger Alan Barzilay

Tópicos
- O Modelo Básico
- Detalhamento Formal
- Modelo CBOW Completo
- Otimizações no Modelo CBOW
- Formas de Avaliar o Word2vec
- Outro Embeddings Pré-treinados
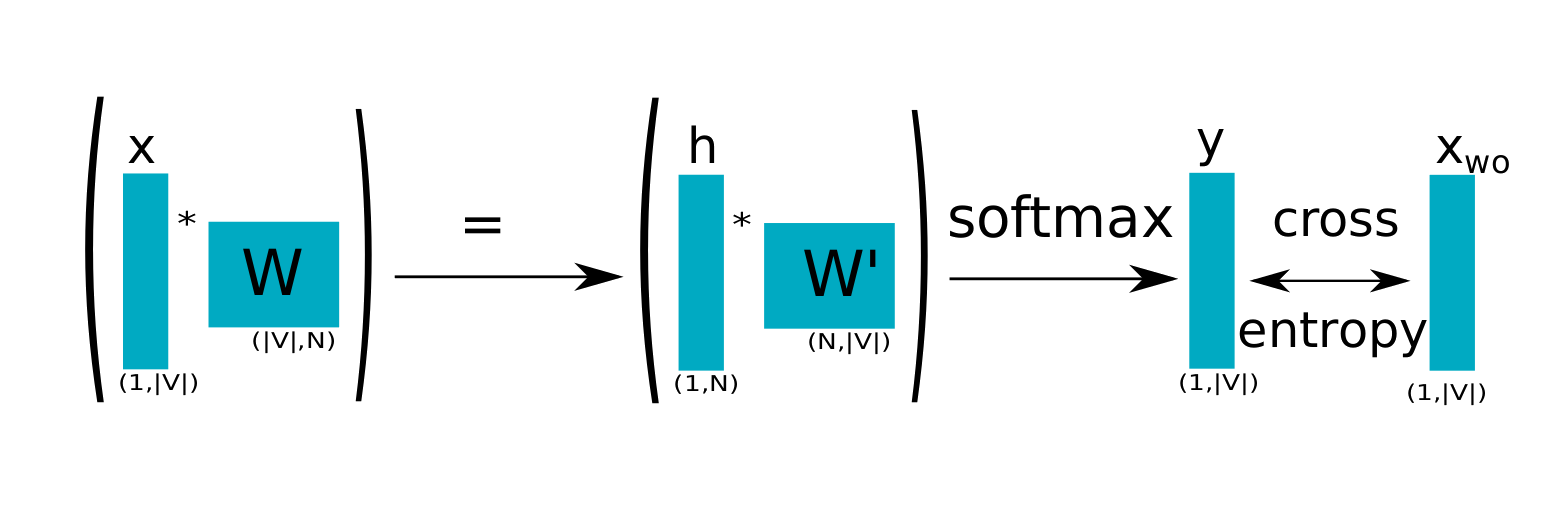
CBOW Esquematizado
Dados (\(x_{e}\), \(x_{s}\)) one-hot de (\(p_{e}\), \(p_{s}\)) e \(x=x_{e}\), \(x'=x_s\):
\[h_i = \sum_{k=1}^{m}w_{k,i} x_{k}, i = 1, \dots, n ~\Longrightarrow~~~ h = W \cdot x\]
\[u_j = \sum_{\ell=1}^{n} w'_{\ell,j} h_{\ell}, j = 1, \dots, m ~\Longrightarrow~~~ u = W' \cdot h\]
\[y_j = P(p_{j}|p_{e}) = \frac{\exp(u_j)}{\sum_{k=1}^{m} \exp(u_{k})}, j = 1, \dots, m ~\Longrightarrow y = Softmax(u)\]
\[\lambda = CE(x',y) = -\sum_{k=1}^{m} {x'}_k \log(y_k)\]
CBOW Simplificado
Pelo formato 1-hot de \(x\) e \(x'\):
\[h = w_{e}\]
\[u = W' \cdot w_{e} \]
\[y_j =\frac{\exp(u_j)}{\sum_{k=1}^{m} \exp(u_{k})} \]
\[\lambda = - u_{s} + \log \left(\sum_{k=1}^{m} \exp (u_{k})\right)\]
onde \(s\) é o índice de \(p_{s}\), \(e\) é o índice de \(p_{e}\) e \(j\) é o índice de \(p_{j}\).
Simplificando CBOW Simplificado
Por retropopagação, \(W'\) é atualizada:
\[{w_{ij}^{\prime}}^{(new)} = {w_{ij}^{\prime}}^{(old)} - \alpha \, \varepsilon_{j} \, h_{i}\]
Em notação vetorial
\[{W^{\prime}}^{(new)} = {W^{\prime}}^{(old)} - \alpha \, \varepsilon \, h^T\]
onde \(\varepsilon=y -x_{s}\)
CBOW Simplificado: atualizaçãoo
E a matriz \(W\) também é atualizada notação matricial:
\[W^{(new)} = W^{(old)} - \alpha DW'\]
para \(D\) uma matriz diagonal onde \(d_{ii} = y_i\) quando \(i \neq s\) e \(d_{ss} = y_s -1\)
\(d_{ij} = 0\) para \(i \neq j\)
CBOW Simplificado: atualização
Repita este processo com exemplos do córpus, o efeito se acumula e como resultado palavras com contextos semelhantes ficarão próximas umas das outras.
O modelo captura as estatísticas de coocorrência usando a distância do cosseno
BOW Simplificado: treinamento
