Representando Palavras & Embeddings
Parte 04: Embeddings
Marcelo Finger Alan Barzilay

Tópicos
- O problema de representação de sentenças
- Representações alternativas
- Semântica vetorial de palavras
- Embeddings
Embeddings
Embeddings
Um embedding, ou uma imersão, é uma representação em \(\mathbb{R}^n\) das palavras.
Cada palavra existe como um ponto em um espaço vetorial de dimensão menor que o tamanho do vocabulário.
Batata
Ônibus
[ 2.34, 4.75, 17.01, -0.223]
[-2.31, 3.34, 1.425, -9.354]
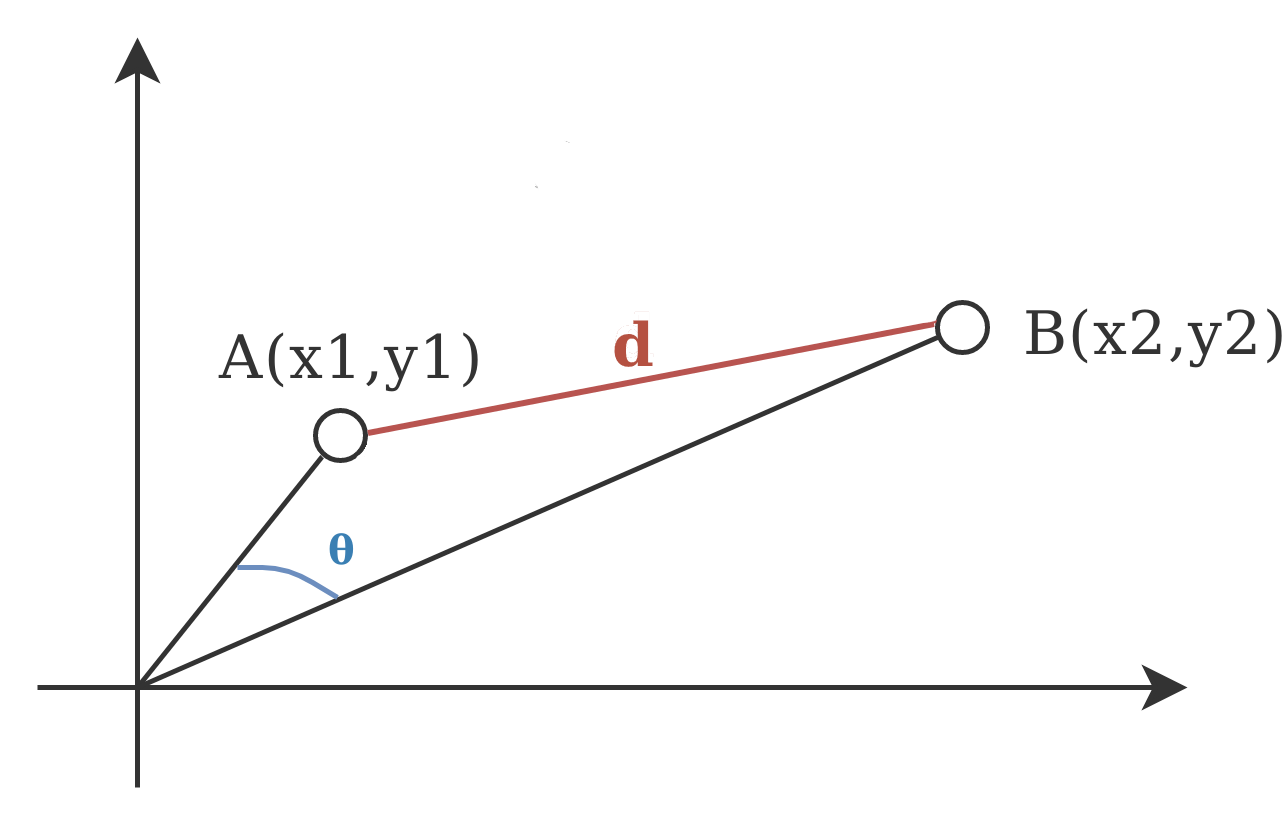
Distancia Euclidiana
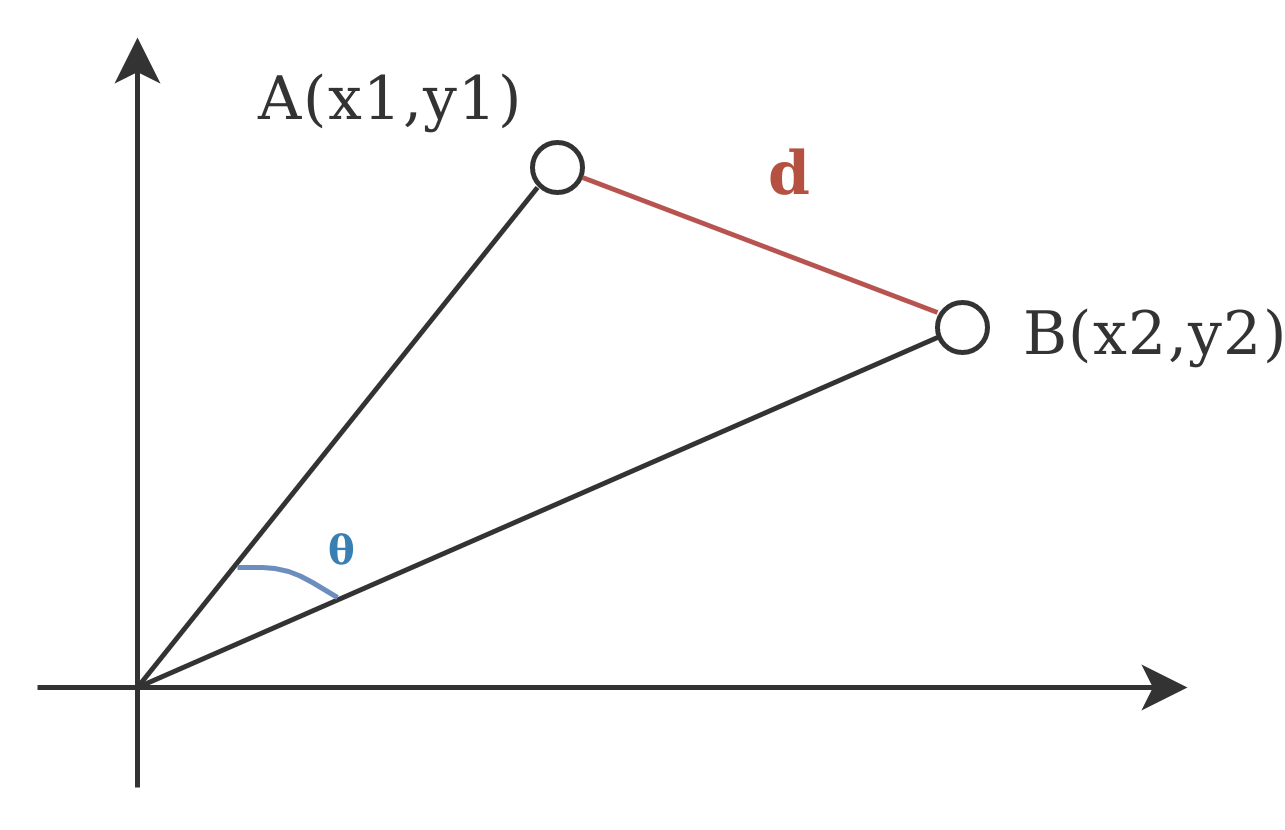
Similaridade Cosseno
Similaridade Cosseno
Similaridade Cosseno é utilizada quando a magnitude do vetor não é relevante ou pode não carregar um significado real.
Embedding LookUp Table
Dimensão de Embedding n
Tamanho do
Vocabulário m
Como gerar um embedding?
Seria interessante termos um embedding que apresente noções de similaridade entre as palavras. Palavras similares estarão próximas nesse espaço.
Podemos tratar a camada de embedding de nossa rede como mais uma camada a ser treinada. A matriz que representa os embeddings será atualizada a cada iteração assim como os outros parâmetros da rede.
tf.keras.layers.Embedding(
input_dim, output_dim, embeddings_initializer='uniform',
embeddings_regularizer=None, activity_regularizer=None,
embeddings_constraint=None, mask_zero=False, input_length=None, **kwargs
)
Padding
Redes Neurais necessitam de entradas de tamanho constante. Se cada frase é uma entrada, como garantimos isso?
Eu fui no parque e comprei um sorvete
Eu tirei um cochilo <PAD><PAD><PAD><PAD>
Mesmo
comprimento
8
Uma solução é definir um token especial <PAD> que serve para deixar sentenças de comprimento diferente com um mesmo tamanho:
Padding
from tensorflow.keras import layers
layers.experimental.preprocessing.TextVectorization(
max_tokens=None,
standardize=LOWER_AND_STRIP_PUNCTUATION,
split=SPLIT_ON_WHITESPACE,
ngrams=None,
output_mode="int",
output_sequence_length=None,
pad_to_max_tokens=True,
**kwargs
)
OOV - Out of Value
Como lidar com palavras fora do vocabulário?
<OOV> Serve como um token especial para onde todas as palavras encontradas que não pertencem ao nosso vocabulário são mapeadas.
É possivel definir multiplos buckets OOV para que os outliers não sejam todos mapeados para o mesmo token.
