Representando Palavras & Embeddings
Parte 02: Representações alternativas
Marcelo Finger Alan Barzilay

Tópicos
- O problema de representação de sentenças
- Representações alternativas
- Semântica vetorial de palavras
- Embeddings
Representações Alternativas
Bag of Words
Eu gosto de batata.
Eu gosto de estudar.
Vocabulario: [“Eu”, “gosto”, “de”, “batata”, “estudar”]
[1,1,1,1,0]
[1,1,1,0,1]
Batata gosto de eu.
Não leva em conta ordem, só uma sacola de palavras soltas:
[1,1,1,1,0]
Bag of Words
from tensorflow.keras import layers
layers.experimental.preprocessing.TextVectorization(
max_tokens=None,
standardize=LOWER_AND_STRIP_PUNCTUATION,
split=SPLIT_ON_WHITESPACE,
ngrams=None,
output_mode="binary",
output_sequence_length=None,
pad_to_max_tokens=True,
**kwargs
)
Podemos usar essa abordagem para anotar frequências e não só presença de tokens.
Vocabulario: [“Eu”, “gosto”, “de”, “batata”, “e”, “estudar”, “bicicleta”, “morango”]
Eu gosto de batata e gosto de estudar
[1,2,2,1,1,1,0,0]
from tensorflow.keras import layers
layers.experimental.preprocessing.TextVectorization(
max_tokens=None,
standardize=LOWER_AND_STRIP_PUNCTUATION,
split=SPLIT_ON_WHITESPACE,
ngrams=None,
output_mode="count",
output_sequence_length=None,
pad_to_max_tokens=True,
**kwargs
)
\(n\)-gramas
Eu nasci em São Paulo.
Um token passa a ser um conjunto de \(n\)-palavras ao invés de apenas uma única palavra.
2-grams: Eu nasci, nasci em, em São, São Paulo.
3-grams: Eu nasci em, nasci em São, em São Paulo
4-grams: Eu nasci em São, nasci em São Paulo
from tensorflow.keras import layers
layers.experimental.preprocessing.TextVectorization(
max_tokens=None,
standardize=LOWER_AND_STRIP_PUNCTUATION,
split=SPLIT_ON_WHITESPACE,
ngrams=None,
output_mode="int",
output_sequence_length=None,
pad_to_max_tokens=True,
**kwargs
)
\(n\)-gramas
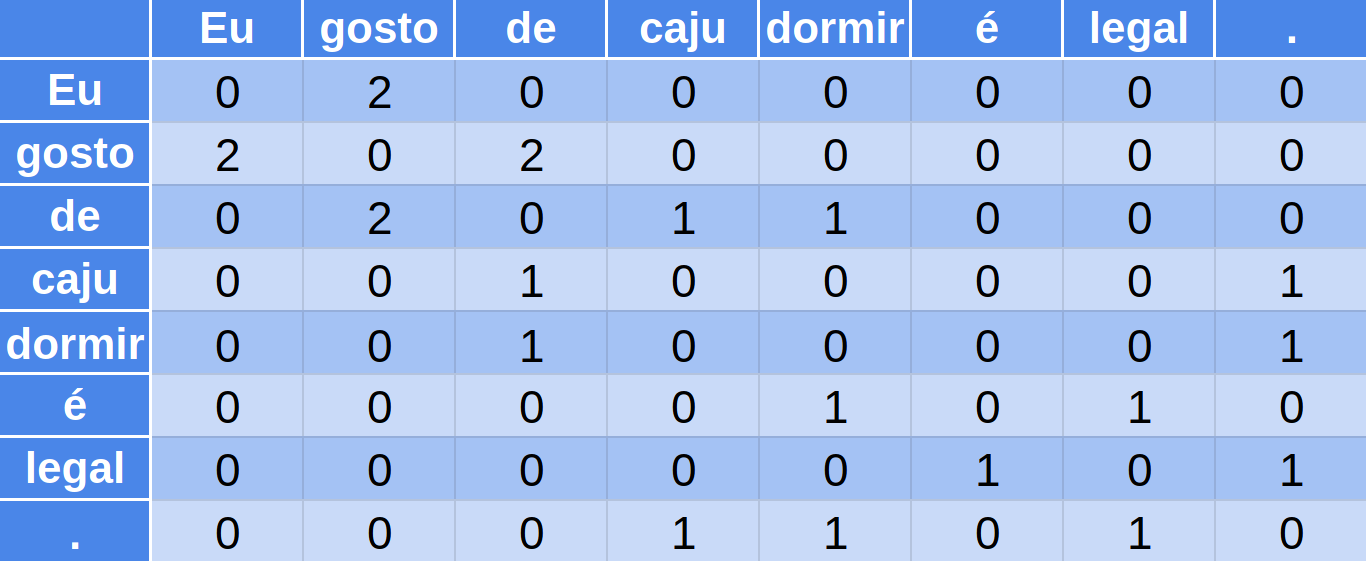
Matriz de Co-ocorrência
-
Eu gosto de caju.
-
Eu gosto de dormir.
-
dormir é legal.
TF-IDF
TF-IDF ou Term Frequency – Inverse Document Frequency é uma medida de relevância de um termo para um dado texto.
Um termo que aparece frequentemente deve ser importante, mas se esse é um termo comum em textos num geral (como preposições e artigos) ele não deverá ser tão importante.
$$ tf\_idf_{\blue t, \blue D}= tf_{\blue t, \blue D}\times \log\left( \frac{N}{df_{\blue t, \blue D}}\right)$$
TF-IDF
termo t na coleção de documentos D
\(tf_{\blue t, \blue D}\) : frequência média de t em documentos de D
\(df_{\blue t, \blue D}\) : n. de documentos contendo t em D
\(N\) : n. de documentos em D

Gato
x4
x1000
10.000.000
Documentos
Documento com
100 palavras
TF-IDF
from tensorflow.keras import layers
layers.experimental.preprocessing.TextVectorization(
max_tokens=None,
standardize=LOWER_AND_STRIP_PUNCTUATION,
split=SPLIT_ON_WHITESPACE,
ngrams=None,
output_mode="tf-idf",
output_sequence_length=None,
pad_to_max_tokens=True,
**kwargs
)
Em todos estes métodos, a representação e uso de memória crescem conforme o tamanho do vocabulário.
Palavras similares possuem representações ortogonais. Não existe noção de similaridade.
