Marcelo Finger Alan Barzilay

RNN's
Parte 04: Problemas Advindos da Recorrência
Conteúdos
- Recorrência Neural
- Treinamento Recorrente
- Modelos Sequência pra Sequência
- Problemas que Advem da Recorrência
- Soluções para Redes Profundas
Problemas de redes profundas
Vanishing & Exploding Gradient
O gradiente de uma camada é calculado pela regra da cadeia e portanto é um produto do gradiente de todas as camadas anteriores.
Vanishing & Exploding Gradient
O que acontece com uma camada se alguma das camadas anteriores possuir um gradiente muito pequeno? E se ele for muito grande?
Exploding Gradient
Com um gradiente muito elevado é possível que ao realizarmos uma etapa de backpropagation tomemos um passo muito grande que gere um update ruim (aumente a Loss).
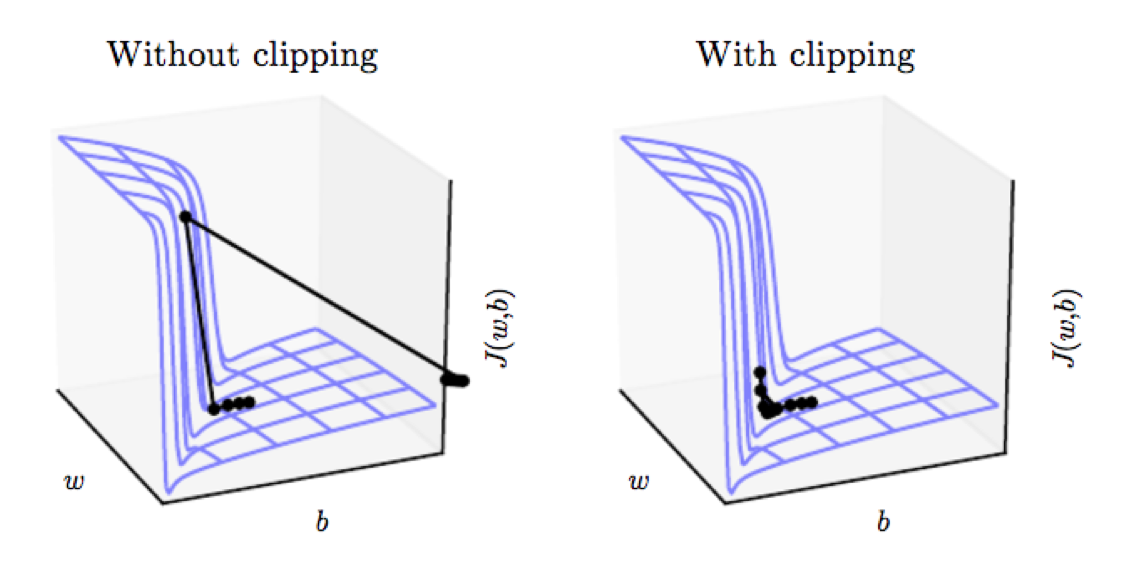
Se o passo for acima de um limite definido, nós diminuímos a magnitude do passo e mantemos a direção.
Gradient Clipping
from tensorflow import keras
keras.optimizers.SGD(lr=0.01, momentum=0.9, clipnorm=1.0)
Vanishing Gradient
O gradiente pode ser visto como uma medida da influência do passado no futuro.
Com um gradiente baixo a influência passa a ser baixa. Impossível capturar relações distantes.
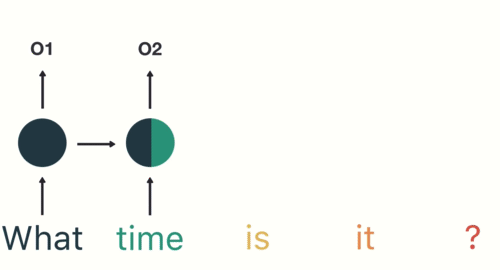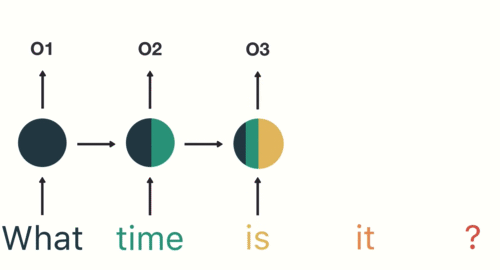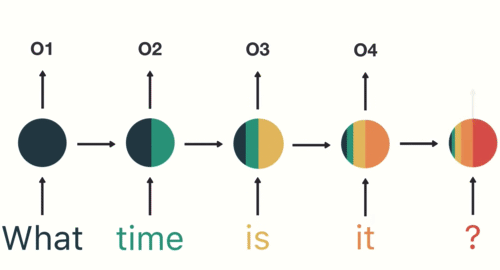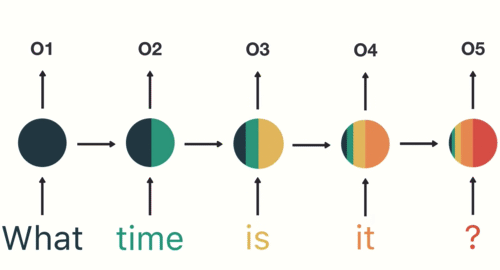
Vanishing Gradient
Isso é um problema apenas de redes recorrentes?
Não! Toda rede profunda sofre destas questões, mas redes recorrentes são especialmente instáveis devido a utilização da mesma matriz de pesos.
