Word2vec
Parte 04: Eficiência no Word2vec
Marcelo Finger Alan Barzilay

Tópicos
- O Modelo Básico
- Detalhamento Formal
- Modelo CBOW Completo
- Otimizações no Modelo CBOW
- Formas de Avaliar o Word2vec
- Outro Embeddings Pré-treinados
CBOW Completo Esquematizado
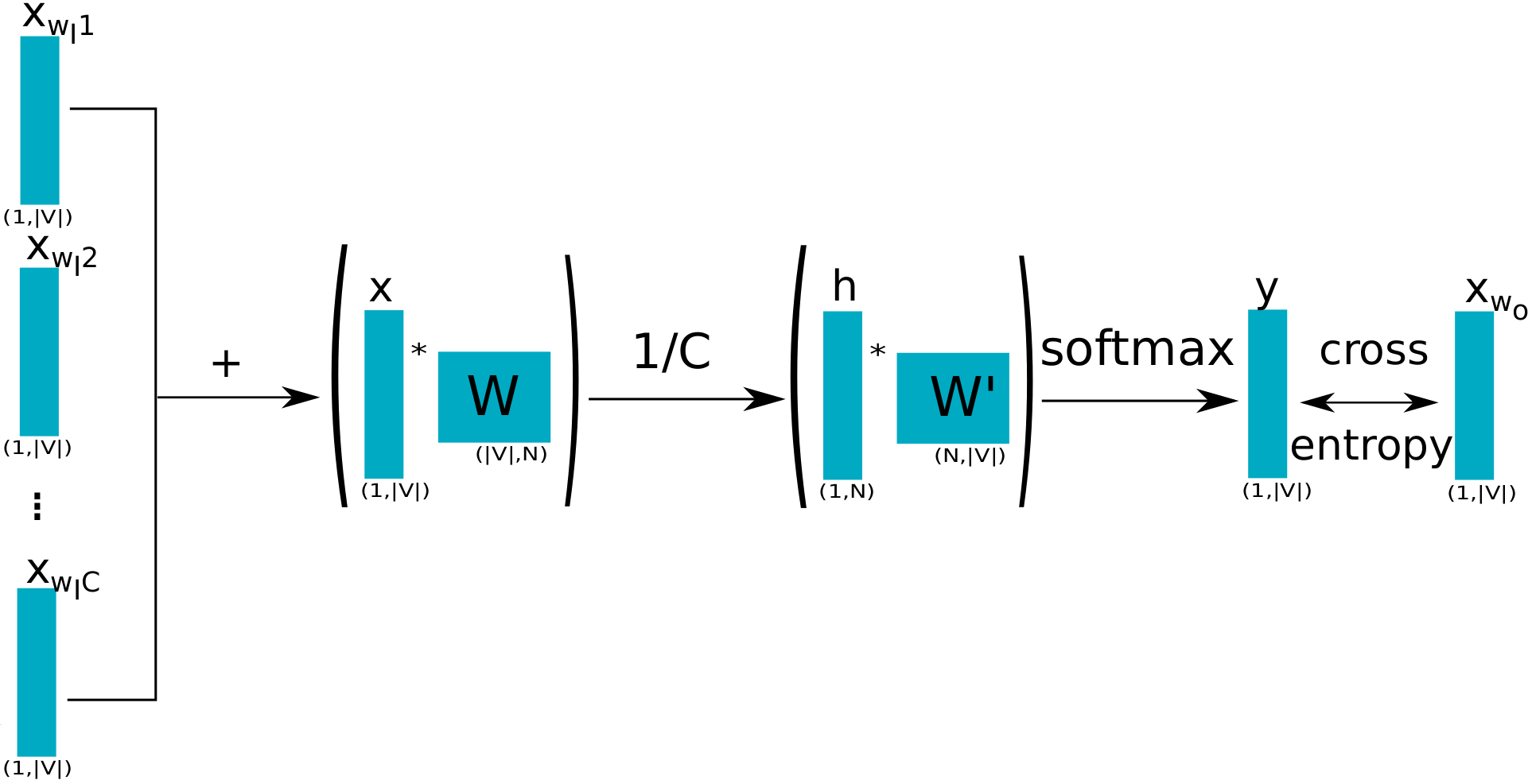
A largura do modelo é o tamanho do vocabulário:
\[h = \frac{1}{C}W(x_1+x_2+x_3+x_4) ~~~ u = W' h\]
Final da segunda fase percorre todo o vocabulário:
\[y = Softmax(u), ~~~ y_j = \frac{\exp(u_j)}{\sum_{k=1}^{m} exp(u_k)}\]
Esta última etapa será aproximada
Ao final, a palavra \(p\) será associada a \(p\)-ésima linha de \(W\), \(w_p\)
Deep Learning Raso e Largo
Nunca me acostumei com o cantor dessa banda, e nem ...
\[([\textcolor{FireBrick}{com, o, dessa, banda}], cantor) \Longrightarrow \left\{\begin{array}{l}(com, cantor, 1)\\ (o, cantor, 1) \\ (dessa, cantor, 1)\\ (banda, cantor, 1)\\ (\textcolor{purple}{\bf todo~o~resto !}, cantor, {0}) \end{array} \right. \]
Amostragem negativa: escolha algumas palavras de todo o resto! (Palavras negativas) para atualizar.
As demais palavras não são afetadas
Amostragem Negativa
Mantemos \( x , W, W ^ {\prime}, h\) como antes. Para obter amostras de palavras negativas, empregamos uma distribuição \(P_ {j} (p) \) sobre todas as palavras do corpus. Por exemplo:
\[P(p_j) = \frac {f (p_j)} {\sum f (p_i)} = \frac {\textrm{Cont} (p_j) ^ {\frac {3} {4} }} {\sum_{i=1} ^ {m -1} \textrm {Cont} (p_i) ^ {\frac {3} {4}}}\]
\(P(p_j)\): probabilidade de \(p_j\) ser amostrada. Fixe \(K, 5 \leq K \leq 20\).
Para cada \(s\), amostramos \(p_ {i_ {1}}, \dots, p_{i_ {K}}\); evite \(p_ s\) dentre eles.
\(f (p_j) = \textrm{Cont} (p_j) ^ {\frac {3} {4}}\): empírico com bons resultados na prática
Amostragem negativa na saída
(\(p_{e}\),\(p_{s}\))
Exemplo(s) Positivo(s)
(\(p_{i_{1}}\),\(p_{s}\)), \(\dots\), (\(p_{i_{K}}\),\(p_{s}\))
Exemplos Negativos
Exemplos positivos e negativos
Uma camada de ativação é inserida para a probabilidade de (\(p_e\),\(p_s\)) co-ocorrer no córpus (em uma janela \(C\))
\[P(D=1 \;|\; p_e,p_s) = \sigma(w_{e}^{\prime} \; .^{T} \;h)\]
Probabilidade de (\(p_{i_k}\),\(p_s\)) não co-ocorrerem no córpus:
\[P(D=0 \;|\; p_{i_k},p_s)= \sigma(-w_{i_k}^{\prime} \; .^{T} \;h)\]
O objetivo do treino é maximizar as probabilidades:
\(P(D=1 \;|\; p_e,p_{s})\), \(P(D=0 \;|\; p_{i_{1}},p_{s}), \dots , \; P(D=0 \;|\; p_{i_{K}},p_{s})\)
Nova otimização
Minimizar a seguinte função de erro:
\(\lambda = -\log \left(p(D=1 \;|\; p_e,p_s) \, .\, \prod_{k=1}^{K} p(D=0 \;|\; p_{i_{k}},p_s)\right) \)
\(~~~~ = - \left(\log p(D=1 \;|\; p_e,p_s) + \log\left(\prod_{k=1}^{K} p(D=0 \;|\; p_{i_{k}},p_{s})\right)\right)\)
\(~~~~ = - \left(\log p(D=1 \;|\; p_e,p_s) + \sum_{k=1}^{K}\log p(D=0 \;|\; p_{i_{k}},p_{s})\right)\)
\(~~~~ = - \log \sigma(w'_{s} \; .^{T} \; h) - \sum_{k=1}^{K}\log \sigma(- w'_{{i_{k}}} \; .^{T} \; h)\)
Amostragem Negativa: o Modelo
Atualiza apenas \(K+1\) colunas de \(W'\) e linhas de \(W\):
\({w^{\prime}_{s}}^{(new)} = {w^{\prime}_{s}}^{(old)} - \alpha \, (\sigma( w_{s}^{\prime} \; .^{T} \; h) -1) \, h\)
\({w^{\prime}_{i_{k}}}^{(new)} = {w^{\prime}_{i_{k}}}^{(old)} - \alpha \, \sigma(-w_{i_{k}}^{\prime} \; .^{T} \; h) \, h\)
\(W^{(new)} = W^{(old)} - \alpha \, X^{T}\)
onde as colunas não-nulas de \(X\) são:
\[X_s = (\sigma(w_{s}^{\prime} \; .^{T} \; h) -1) \, w_{s}^{\prime}; X_{i_k} = \sum_{k=1}^{K}\sigma(-w_{i_{k}}^{\prime} \; .^{T} \; h)w_{i_{k}}^{\prime}\]
Deep learning com 1,5 camadas !
Amostragem Negativa: atualização
